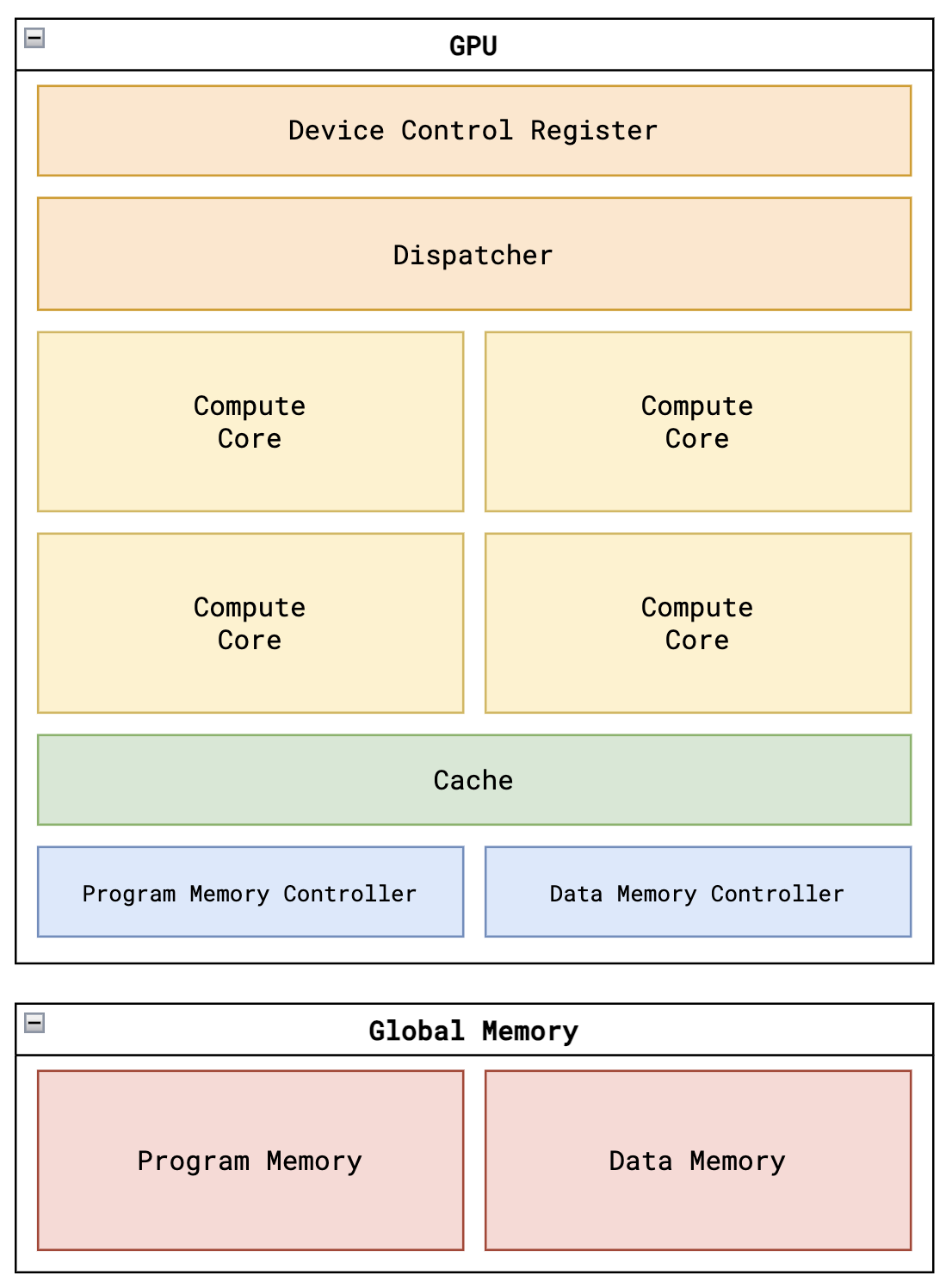
// Compute Cores genvar i; generate for (i = 0; i < NUM_CORES; i = i + 1) begin : cores // EDA: We create separate signals here to pass to cores because of a requirement // by the OpenLane EDA flow (uses Verilog 2005) that prevents slicing the top-level signals reg [THREADS_PER_BLOCK-1:0] core_lsu_read_valid; // one hot reg [DATA_MEM_ADDR_BITS-1:0] core_lsu_read_address [THREADS_PER_BLOCK-1:0]; reg [THREADS_PER_BLOCK-1:0] core_lsu_read_ready; reg [DATA_MEM_DATA_BITS-1:0] core_lsu_read_data [THREADS_PER_BLOCK-1:0]; reg [THREADS_PER_BLOCK-1:0] core_lsu_write_valid; reg [DATA_MEM_ADDR_BITS-1:0] core_lsu_write_address [THREADS_PER_BLOCK-1:0]; reg [DATA_MEM_DATA_BITS-1:0] core_lsu_write_data [THREADS_PER_BLOCK-1:0]; reg [THREADS_PER_BLOCK-1:0] core_lsu_write_ready;
// Pass through signals between LSUs and data memory controller // Load/Store Unit genvar j; for (j = 0; j < THREADS_PER_BLOCK; j = j + 1) begin localparam lsu_index = i * THREADS_PER_BLOCK + j; always @(posedge clk) begin lsu_read_valid[lsu_index] <= core_lsu_read_valid[j]; lsu_read_address[lsu_index] <= core_lsu_read_address[j];
lsu_write_valid[lsu_index] <= core_lsu_write_valid[j]; lsu_write_address[lsu_index] <= core_lsu_write_address[j]; lsu_write_data[lsu_index] <= core_lsu_write_data[j]; core_lsu_read_ready[j] <= lsu_read_ready[lsu_index]; core_lsu_read_data[j] <= lsu_read_data[lsu_index]; core_lsu_write_ready[j] <= lsu_write_ready[lsu_index]; end end
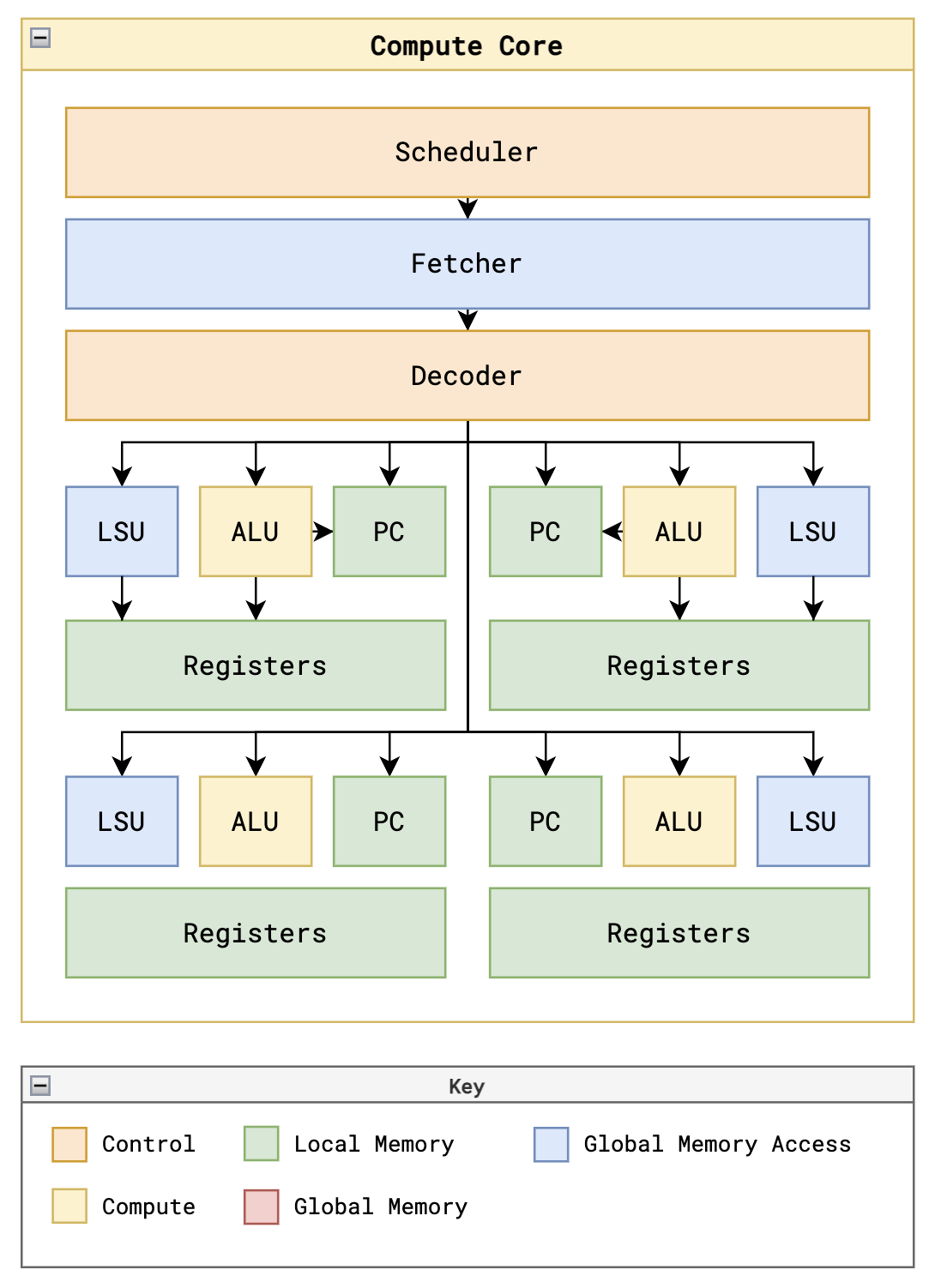
LSU是Load & Store Unit,每个thread有单独的LSU,这里localparam lsu_index = i * THREADS_PER_BLOCK + j; 是因为 i 表示 core的index,j 表示 thread的index,比如 有2个core,每个core里4个thread
第一个core里:
core[0] thread[0] LSU[0]
core[0] thread[1] LSU[1]
core[0] thread[2] LSU[2]
core[0] thread[3] LSU[3]
那么第二个core就需要重新分配LSU的index了,因为LSU就那一个信号通道:
i * THREADS_PER_BLOCK + j = 1 * 4 + 0 = 4
core[1] thread[0] LSU[4]
core[1] thread[1] LSU[5]
core[1] thread[2] LSU[6]
core[1] thread[3] LSU[7]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// Compute Cores genvar i; generate for (i = 0; i < NUM_CORES; i = i + 1) begin : cores // EDA: We create separate signals here to pass to cores because of a requirement // by the OpenLane EDA flow (uses Verilog 2005) that prevents slicing the top-level signals reg [THREADS_PER_BLOCK-1:0] core_lsu_read_valid; // one hot reg [DATA_MEM_ADDR_BITS-1:0] core_lsu_read_address [THREADS_PER_BLOCK-1:0]; reg [THREADS_PER_BLOCK-1:0] core_lsu_read_ready; reg [DATA_MEM_DATA_BITS-1:0] core_lsu_read_data [THREADS_PER_BLOCK-1:0]; reg [THREADS_PER_BLOCK-1:0] core_lsu_write_valid; reg [DATA_MEM_ADDR_BITS-1:0] core_lsu_write_address [THREADS_PER_BLOCK-1:0]; reg [DATA_MEM_DATA_BITS-1:0] core_lsu_write_data [THREADS_PER_BLOCK-1:0]; reg [THREADS_PER_BLOCK-1:0] core_lsu_write_ready;