8B/10B编码
Reference:https://zhuanlan.zhihu.com/p/560350350
编码的目的
目的一:在数据里嵌入时钟
你提到的内容集中在8b/10b编码如何通过数据流中的边沿来嵌入时钟信号,并且探讨了这种方式在高速串行传输中的优势及潜在的限制。我会依据你的描述进行更具体的解释。
8b/10b编码与时钟恢复
8b/10b编码是一种数据编码方法,用于将8位数据编码为10位代码。这种编码确保了数据流中具有足够的信号变化(或称边沿),这些边沿对于接收端正确恢复发送端的时钟信号至关重要。通常,发送端的时钟信号用于控制数据何时被发送,而接收端必须能准确地同步这个时钟以正确读取数据。通过8b/10b编码,接收端可以从连续接收的数据中恢复出这一时钟,而不需要单独的时钟线,这称为“自恢复时钟”或“嵌入式时钟”。
串行通信的优势
使用8b/10b编码的串行通信技术,可以克服并行通信中常见的几个问题:
- 飞行时间限制和时钟偏斜:并行总线在高速传输时,不同的数据线长度和质量可能导致数据到达的时间不同,即时钟偏斜。这在串行传输中基本不是问题,因为数据是连续通过单一通道发送。
- 电磁干扰(EMI)和布线问题:高频时钟在并行总线中可能导致严重的电磁干扰,同时并行总线需要多条线同时布线,这在物理设计上是一个挑战。串行通信通过减少所需的物理连接,降低了EMI的风险,简化了布线需求。
这里请注意,串行总线是当前高速接口的主流方案,但并不意味着串行方案能完全避免例如“Skew”问题的影响,如果传输都是一个lane那当然没影响,但为了提高带宽,一般都不会是一个lane。比如PCIe中的X1,X4,X16,X32这些各个lane仍然会存在偏斜的问题,但收发器本身会处理这些偏斜,当然这不在本文讨论范围。
Parallel Communication 并行通信
下图的并行通信 Parallel Communication做对比:
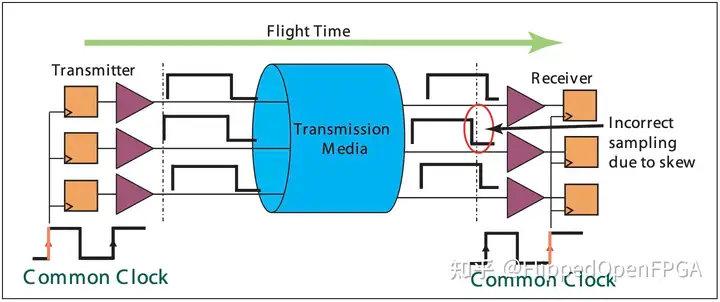
提到的通用时钟(common clock)、时钟偏斜(clock skew)、数据偏斜(data skew)、飞行时间(flight time)、电磁干扰(EMI, Electromagnetic Interference)、以及时钟布线问题,都是并行传输中需要解决的关键技术点。下面我会逐一简单解释这些概念及其带来的挑战:
通用时钟与时钟偏斜
在并行传输系统中,所有的数据线通常都由一个通用时钟控制,以确保数据的同步发送和接收。时钟偏斜指的是由于布线长度不一、环境影响或其他物理特性差异导致的时钟信号在不同数据线上到达接收端的时间不同。这种Skew会导致数据同步问题,从而影响整个系统的性能和可靠性。
数据偏斜
数据偏斜类似于时钟偏斜,但它指的是数据本身在不同的线路上到达时间的差异。即使时钟完全同步,数据线之间的物理或电气差异也可能导致数据偏斜,同样影响数据的正确接收。
飞行时间
飞行时间是指信号从发送端到接收端所需要的时间。随着通用时钟频率的增加,要求每一次钟周期内信号必须被正确接收和处理。如果飞行时间超过了一个时钟周期,那么信号将不会在正确的时钟边沿到达接收端,导致数据错误或丢失。
EMI与时钟布线问题
高频时钟信号容易产生电磁干扰,这不仅影响并行传输线路本身,还可能影响到周围的电子设备。此外,高速 Parallel 传输需要大量的布线以支持多个数据线和时钟线,这在Physical Design上是一个挑战,尤其是在空间受限或布线密度高的设备中更为复杂。
应对策略
为了解决这些问题,设计师可能采用多种策略:
- 使用差分信号:通过差分信号技术减少EMI并提高信号的抗干扰能力。
- 优化布线设计:通过精心设计布线来尽量减少时钟偏斜和数据偏斜。
- 采用更高级的时钟技术:如使用源同步时钟(source synchronous clocking)或采用嵌入式时钟恢复技术,如上文提到的8b/10b编码。
目的二:保持DC平衡
这里结合PCIe(Peripheral Component Interconnect Express)的例子来详细解释:
DC 平衡 DC Balance 的重要性
在高速数据传输中,保持DC平衡指的是在传输的数据流中,“0”和“1”的数量保持大致相等。这一平衡有助于:
- 减少电磁干扰(EMI):因为频繁的电平变换可以抑制信号长时间在高或低状态,降低干扰。
- 便于信号的AC耦合:在使用AC耦合的通信系统中(比如PCI Express),如果信号中的“0”和“1”长时间不平衡(即没有DC平衡),那么信号会逐渐向一个电平偏移,造成累积的直流成分。信号可能因直流成分过大而不能通过AC耦合电容,导致信号失真或丢失。
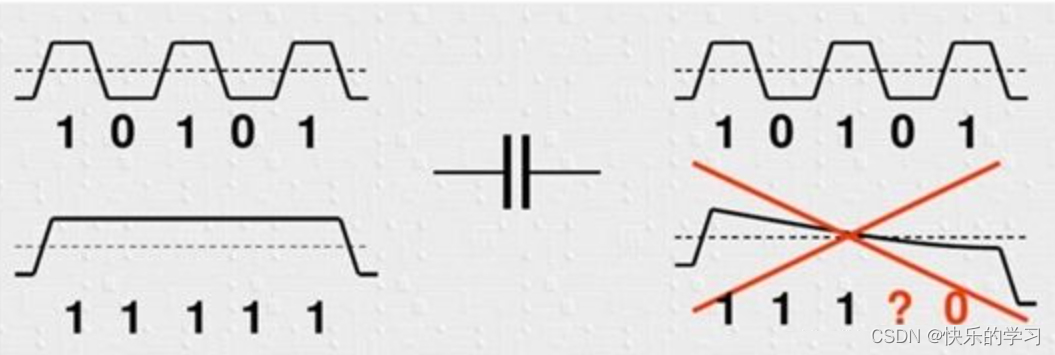
编码方式
为了实现DC平衡,常用的一种方法是采用特殊的编码方式,如8b/10b编码,该编码规则确保了数据中“0”和“1”的平衡,并限制了连续相同数字的长度。在这种编码中,每5个连续的“1”或“0”后必须插入一位相反的数字,从而防止信号在一个电平上持续太久,导致链路上的直流偏移 DC Offset。
AC耦合 AC Coupling 和频率的影响
在传输高速信号时,AC耦合通过使用电容来连接信号路径,这样做的目的是只允许交变信号(AC,即变化的信号部分)通过,而阻挡直流成分(DC,即恒定的信号部分)。AC耦合的主要优点是能够消除直流偏移(DC Offset)。直流偏移是指信号平均电平的偏离,这种偏移可能会对电子系统的性能产生负面影响,比如使放大器饱和或者使信号处理更加复杂。通过电容连接,任何的直流偏移都被电容阻挡,因此不会影响到接收端的电路。
在AC耦合系统中,当信号频率变化时,通过耦合电容的阻抗也会变化。频率越高,电容的阻抗越低,信号更容易通过;频率越低,电容的阻抗越高,信号传输就更困难。因此,如果数据流中出现长序列的连续“0”或“1”,相当于降低了信号的频率,可能导致信号无法有效传输。
极性偏差 Polarity Disparity 的控制
极性偏差是指在编码的数据中“1”的数量与“0”的数量的差异。如你所述,正极性偏差表示“1”多于“0”,副极性偏差则相反。通过控制这种偏差,可以进一步保证编码后的数据既保持DC平衡,又避免长时间的电平连续性。例如,在10位数据中,通过确保“0”和“1”的数量差不超过2,可以有效地维持信号完整性 Signal Integrity 和防止偏差过大。
目的三:加强错误检测
原始的8位数据,因为是8 bits,所以有 $2^8 = 256$ 个可能的值。而在10位的编码中,可以有 $2^{10} = 1024$ 个可能的编码。在理想的情况下,如果是1对1映射,我们会从这1024个可能的10位编码中选出256个来直接对应256个8位的原始数据。但8b/10b编码采用了不同的策略来优化信号传输和错误控制。
为了保持 DC 平衡(即使数据中的0和1的数量尽量平衡),避免极性偏差,一些8位数据在映射到10位时不仅仅是对应一个10位的值,而是可以对应两个不同的值,分别用来适应正极性偏差和负极性偏差。这种方式实际上使得某些8位数据通过两种不同的10位编码来表达,以此来调整信号的 DC 级别。
因此,每个8位的数据单元实际上可以映射到两个10位的数据单元中,导致512个8位数据单元的编码。此外,10位编码中还包括一些专门用于控制信号的编码,比如帧开始、帧结束标志等,这些也是非数据编码,用于数据传输的控制和管理。
由于总共1024个可能的10位编码中,只有部分被用作有效数据和控制信号的映射,剩余的编码就成为了非法编码。在接收端,如果检测到了这些非法的编码,就可以认为传输过程中发生了错误,从而利用这一机制进行错误检测。
总结来说,8b/10b 编码通过增加每个数据单元的位数,并通过复杂的映射策略来改善信号的DC平衡和提高错误检测的能力。
编码的基本原理
8b/10b 编码确实为数字通信提供了诸多优点,如改善DC平衡和提升错误检测能力,但同时也带来了一定的缺点,尤其是在数据传输效率上。具体来说,将8位(8 bit)数据编码成10位(10 bit)数据,确实引入了20%的额外开销,因为每发送8位的实际数据,就需要发送10位的编码数据,其中2位用于确保编码的特性和目标,而非直接承载用户数据。
为了更好地理解这个开销及其影响,可以比较不同的编码方案。例如,在高速通信协议如 PCIe 3.0 中,使用的是64b/66b 或 128b/130b 编码方式,这些编码方式通过增加原始数据的比特数来减少相对的额外开销,从而提高了数据传输效率。
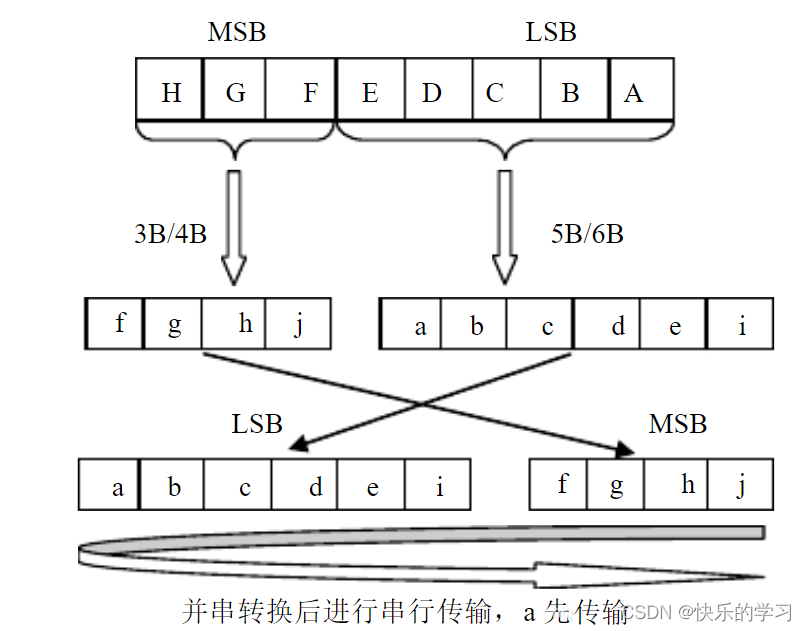
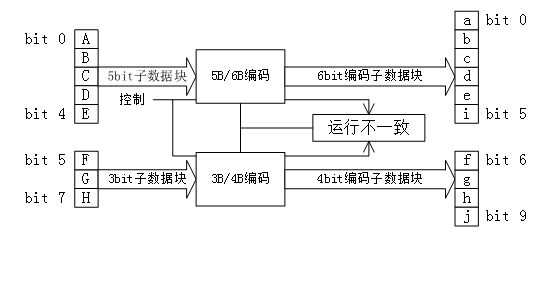
具体到8b/10b编码的实现,这种编码方案并不是简单地将8位数据直接转换为10位数据。实际上,这种编码通过将8位数据分为两部分进行处理以优化编码效率:
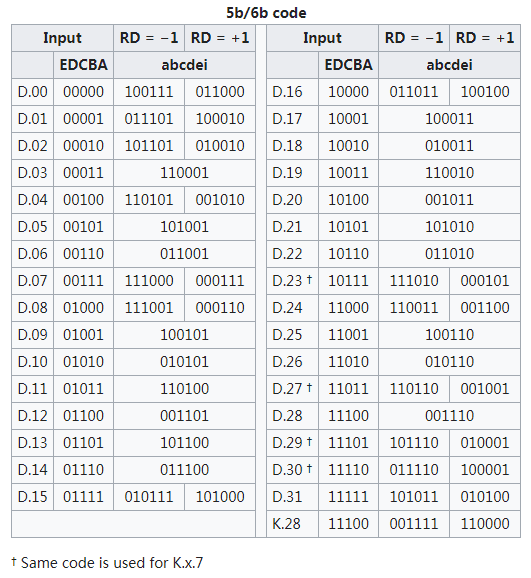
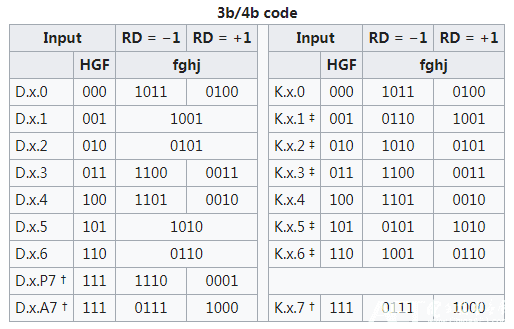
- 低5位(Lower 5 bits):采用5b/6b编码
- 高3位(Upper 3 bits):采用3b/4b编码
最终,这两部分编码结果被合并成一个10位的数据单元。这种分割和重组的方法可以减少编码的复杂性,并优化对芯片面积的需求。
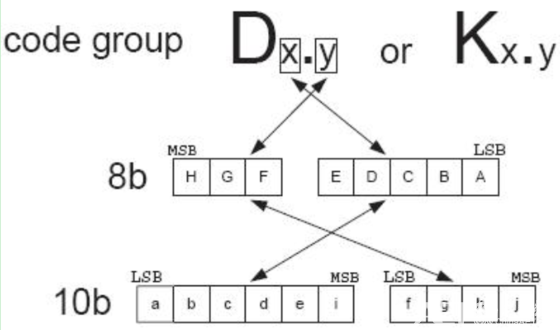
8b/10b编码定义了256种数据映射和12种特殊控制字符的编码,分别用Dx.y和Kx.y来标识,其中“x”代表高3位,而“y”代表低5位。这些特殊控制字符编码通常用于帧的起始与终止,以及其他特定功能,如逗号序列的检测。以PCIe 2.0为例,K27.7和K28.2分别标记了不同类型的数据包的开始。
在 8b/10b 编码中,“Dx.y”和“Kx.y”的格式用来描述不同的10位码字:
- Dx.y (Data) 代表普通的数据码字。这些码字用于传输实际的数据负载。这里的“x”和“y”指的是码字的组成,其中“x”代表高3位,而“y”代表低5位,一起决定了具体的10位码字的形式。
- Kx.y (Control) 代表控制码字,这些特殊的码字用于传输控制信息而不是数据。控制码字常用于帧定界、错误指示、同步等控制功能。和数据码字一样,“x”和“y”指的是码字的具体组成
总结而言,尽管8b/10b编码带来了一定的数据开销,但它通过精巧的编码策略优化了数据传输的质量和可靠性。对于需要高效率和低开销的应用,可以考虑使用更高比特率的编码方案,如64b/66b或128b/130b。
直流平衡(DC balance) 是衡量在一段时间内二进制信号中“0”和“1”数量之间差异的一种方法。理想的直流平衡是“0”和“1”数量完全相等,这有助于减少信号传输过程中的功率损耗和提高信号的完整性。
在8b/10b编码中,直流平衡的控制非常关键:
- 4位子分组(来自原始数据的3位):尽管有16种可能的编码(因为 $2^4=16$),但只有6种编码能实现完美的平衡,即每种编码中“0”和“1”的数量相等。这对于映射3位数据的8种可能值是不够的。
- 6位子分组(来自原始数据的5位):在 $2^6=64$ 种可能的编码中,仅有20种编码是完美平衡的。这同样不足以覆盖5位数据的32种可能性。
由于理想的平衡状态是不可能的,8b/10b编码采用了一种叫做**极性偏差(Running Disparity, RD)**的机制来管理和补偿这种不平衡。极性偏差是一个实时计算的参数,用于记录当前传输过程中“0”和“1”的不平衡度。
在实际编码过程中:
- 如果某个10位编码的不平衡度为+2(即“1”的个数比“0”的个数多2),则该编码被标记为RD-。
- 相对地,如果不平衡度为-2(即“0”的个数比“1”的个数多2),则该编码被标记为RD+。
在传输数据时,根据前一个编码后的极性偏差状态,选择适合的10位编码来继续保持信号的平衡性或进行必要的调整。这种方法虽然增加了编码的复杂性,但也显著提高了数据传输的质量和可靠性。
不一致性(Disparity)
- 不一致性描述的是编码中“1”的数量与“0”的数量之间的差异。标准化的不一致性包括+2、0、-2三种状态:
- +2:表示0的数量比1多两个。
- 0:表示0和1的数量相等。
- -2:表示1的数量比0多两个。
运行不一致性(Running Disparity, RD)
- 运行不一致性是指在数据传输过程中,由于前面所有已发送数据的不一致性累积而产生的状态。
- RD仅有+1和-1两种状态,这分别代表:
- +1:表示1的数量比0多。
- -1:表示0的数量比1多。
- RD的初始值通常设为-1,表明最开始0的数量比1多。
- 下一个RD(Next RD)的值取决于当前的RD和当前6B码或4B码的不一致性。基于当前的RD值,系统会决定使用哪种5B/6B或3B/4B编码映射。
为了实现这种编码方式,通常会使用一张查找表。这张表预先定义了所有可能的输入比特序列及其对应的编码输出,包括它们的不一致性和如何影响RD。
根据当前的RD和即将发送的数据比特序列,发送端可以从查找表中找到合适的编码序列,确保数据的正确传输并维持信号的电气平衡。
编码映射表
将低5位EDCBA按其十进制数值记为x,将高3位按其十进制数值记为y,将原始8bit数据记为D.x.y,依次查表得到相应的转换结果。
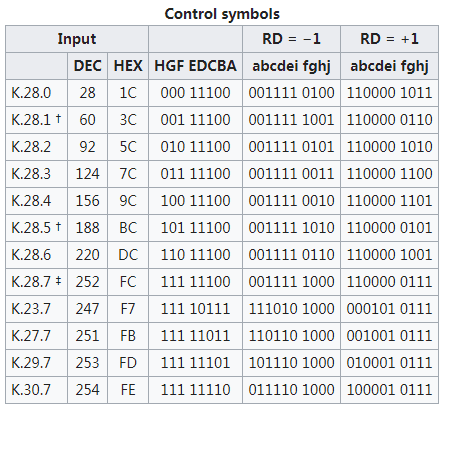
在8B/10B编码系统中,D.x.7、D.x.P7、D.x.A7和K.x.7这些符号都有特定的用途和规则,用以确保数据流的完整性和可靠性。下面我会解释这些符号的具体用途和它们如何帮助避免编码错误。
8B/10B编码中的特殊码组
- D.x.7: 这表示一种数据编码,其中"x"代表8位数据的十进制值,"7"代表这是10位编码中的一种形式。
- D.x.P7 和 D.x.A7: 这些是D.x.7的变种,用来解决特定的编码问题。具体来说,当原始编码可能导致连续出现五个相同的位(0或1)时,会采用这些变种编码来避免此问题。连续的相同位会影响数据的物理层传输效果,例如信号的时钟恢复。
使用逗号码进行校准
- 逗号码(comma codes):如K.28.1、K.28.5、K.28.7,这些是预设的控制字符,用于数据流的同步和校准。逗号码的设计确保它们在数据流中的表现形式是唯一的,不会与数据负载中的任何正常数据序列混淆。
编码决策和限制
- D.x.A7的选择:依据RD(Running Disparity,运行不一致性)的当前值选择D.x.A7的形式。例如,当RD为-1时,在某些特定的"x"值(如17, 18, 20)下使用D.x.A7,而当RD为+1时,在另外一些"x"值(如11, 13, 14)下使用。这样的选择帮助维持电气平衡,防止信号劣化。
- 避免冲突:在某些情况下,使用D.x.A7可能会与预定义的逗号序列产生冲突,从而导致错误的数据解释。在这些情况下(如"x"为23, 27, 29, 30),会改用K.x.7进行编码。
† :在控制代码中,K.28.1 K.28.5 K.28.7 是逗号序列,逗号序列是用来校准用的,如果K.28.7没有被使用,序列0011111 或者 1100000 是不会出现在任何编码中的。
‡ :在实际编码中如果K.28.7可以被使用,一种更复杂的校准规范需要 † 被使用,它们能组合成各种“原语”,在任何情况下多个K.28.7序列不允许被同时使用,它将导致不可探测的逗号序列。
K码和comma字符
- K码:在8B/10B编码中,某些10比特的组合被指定为控制字符,称为K码。这些字符不用来表示数据,而是用来控制传输过程中的特定功能,如帧同步或信号对齐。
- comma字符:在K码中,特定的序列如K28.1、K28.5和K28.7被称为comma字符。这些特定的K码具有独特的比特模式,使得它们在数据流中容易被识别。
comma字符的作用
- 帧的开始和结束:comma字符由于其独特的模式,在数据流中很容易识别。因此,它们经常被用来标示数据帧的开始和结束,帮助接收端确定数据包的边界。
- 信号对齐:comma字符还用于帮助接收设备校正和对齐数据流,确保数据的正确读取。
为什么comma字符不会出现在数据负荷中
- 在设计8B/10B编码时,comma字符的比特模式被选择为不会在正常的数据负荷中出现。这是通过编码规则确保的,即没有任何正常的8比特数据块会被编码为comma字符的10比特模式。这样做的目的是为了避免在数据传输中对comma字符的误识别,从而确保comma字符的作用仅限于控制信号。
编解码设计是在数字通信和存储系统中常用的技术,用于转换数据格式以便更高效地传输和存储。在设计编解码器时,通常会采用以下几种方法:
方法一:查找表法
这种方法通过预先设定的查找表来实现编码和解码。具体做法是:
- 将8位信号映射成10位信号。
- 将输入的8位码组转换为存储地址,然后在查找表中找到相应的10位码组进行输出。
优点:
- 设计简单,开发周期短。
缺点:
- 受到FPGA(现场可编程门阵列)内部存储器读取速度的限制,可能影响编解码速度。
- 增加了芯片的面积和功耗。
方法二:逻辑运算法
直接通过逻辑运算来完成编码和解码的方法。可能涉及复杂的逻辑表达式,例如使用卡诺图(Karnaugh map)化简逻辑。
优点:
- 可以减小芯片内部使用的面积。
缺点:
- 逻辑关系复杂,可能导致大扇入逻辑表达式,限制电路的最高工作速度。
- 增大了对逻辑电路的驱动需求,从而可能增加功耗。
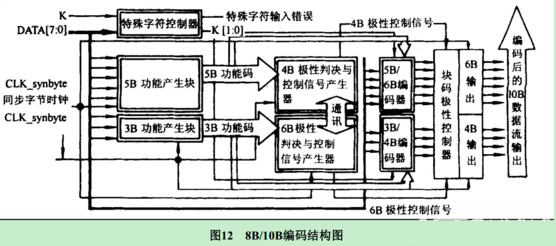
方法三:模块化实现法
这种方法特别适用于8B/10B编码,通过模块化的设计来实现编解码。实现步骤如下:
- 判断输入是特殊字符还是普通数据。
- 如果是特殊字符,根据当前的RD(Running Disparity,运行不一致性)值直接从预设的表中选择对应的编码。
- 如果是数据,将8位数据拆分为3位和5位,然后在RD控制器的控制下并行处理这两部分数据。
优点:
- 清晰的实现流程,易于管理和优化。
- 减小了电路板的面积,提高了工作速度,同时显著降低功耗。
总的来说,选择哪种方法取决于具体的应用需求,包括速度、功耗、芯片面积和开发复杂度等因素。每种方法都有其优势和限制,设计时需要根据实际情况做出权衡。